서론
톰캣 구현 미션을 마무리할 겸 그동안 공부한 간단한 톰캣 내부 구조, Request와 Response, parser를 알아보겠다. 우선 톰캣 만들기 미션 자체의 난이도는 체감상 높았다.
워낙 관련 지식이 없기도 했고, 로우 레벨을 개발하다 보니 새로운 문법들도 많이 보였다. 필자는 원래 CS나 너무 로우 레벨의 개념들에 대해서는 내가 개발하는 서비스와 관계가 별로 없을 거라고 생각했다. 실제로 여태 그랬다.
그런데 이번 미션을 진행하면서 정말 많이 느낀 점이 기본 지식, 즉 Java, CS 등을 더 자세히 공부해야겠다는 생각이 들었다. 괜히 시니어 개발자분들이 화려하고 트렌디한 기술보다 기본을 중시하는 이유도 알 것 같았다.
또한 미션을 진행하면서 톰캣 오픈소스에 총 2개의 PR을 기여했다. 톰캣의 간단한 도메인 지식들과 오픈소스 기여 관련 내용까지 담아보겠다. 최종적으로 구현한 코드는 아래 깃허브에서 볼 수 있다.
Web Server와 Web Application Server는 다르다.
웹 서버와 웹 애플리케이션 서버를 들어본적이 있을 것이다. 하지만 웹 서버와 웹 애플리케이션 서버는 엄연히 다르다. 사용자가 웹 페이지에 요청을 보내게 되면 html과 같은 정적 리소스들은 웹 서버가 처리하고, 데이터베이스를 활용하는 작업 같은 동적 요청은 웹 애플리케이션 서버가 처리한다.
웹 애플리케이션 서버가 웹 서버가 하는 역할을 같이 담당할 수는 있지만, 이전에는 성능상의 문제로 웹 서버와 웹 애플리케이션 서버를 분리하는 것이 정론이었다.
하지만 요즘 웹 애플리케이션에서 제공하는 정적 요청에 대한 처리 기능은 무시할 수 없을 정도로 성장했다. 하지만, 웹 서버에서는 리버스 프록시, 로드 밸런서, 정적 리소스 캐싱과 같은 작업들도 추가적으로 진행할 수 있기 때문에 시스템의 안정성을 위해 웹 서버와 웹 애플리케이션 서버는 분리하는게 좋다.
Nginx를 쓰는 이유를 알아야 한다.
이러한 이유로 여러분들은 웹 서버를 사용하게 될텐데, 웹 서버는 대표적으로 아파치(Apache)와 엔진엑스(Nginx) 등이 있다. 아파치 서버의 경우 한 때 웹 서버 시장의 점유율이 80%에 육박했던 적도 있었다.
하지만 아파치 서버는 c10k라는 큰 문제가 있었는데, c10k 문제는 클라이언트 10,000개 이상의 요청을 동시에 처리할 수 없다는 문제다.
동시에 수 많은 요청을 처리해야한다는 니즈를 느낌과 동시에 소프트웨어가 발전하면서 비동기/이벤트 기반의 소프트웨어가 유행했다. 이 과정에서 웹 서버도 영향을 받았는데, 여기서 아파치의 c10k 문제를 처리하기 위한 비동기/이벤트 기반의 nginx라는 웹 서버가 등장했다.
따라서 이러한 이유 때문에 우리는 아파치 대신 Nginx를 많이 쓰게 된 것이다. 기술을 쓰는 이유와 그 배경을 알아야 한다. 단지 리버스 프록시 기능 때문에 쓰는건 부적절한 근거다. 아파치 웹 서버도 AJP 프로토콜 등을 통해 충분히 처리할 수 있다.
톰캣이 요청을 읽는 법
웹 서버에 대한 서론이 조금 길어졌는데, 본론으로 들어가보자. 여러분들은 톰캣이 어떻게 사용자의 요청을 읽고 처리하는지 알고 있는가? 필자는 톰캣이 요청을 받아서 스프링 프레임워크까지 전달을 해주는 정도만 알고 있었다.
실제로 이번 미션에서는 직접 사용자의 요청을 읽어들이는 과정부터 구현하기 시작했다. 우선 기본적인 Processor를 구현하기 위해 Runnable 인터페이스를 먼저 알아보자.
Runnable
j.l.Runnable 인터페이스는 자바에서 멀티스레딩을 구현하기 위한 인터페이스 중 하나다. 이 인터페이스를 구현하는 클래스는 run 메서드를 구현해야 하는데, 일반적으로 스레드를 생성하고 실행할 때 Runnable 객체를 생성한다.

실제로 서버가 클라이언트와 통신하기 위해서는 위한 커넥터(Connector)가 필요한데, 이는 멀티스레딩 환경에서 비동기 작업을 수행하기 위해 Runnable을 구현하고 있다.
네트워크로 전송된 사용자의 요청을 읽으려면 InputStream, OutputStream, BufferedReader와 같은 I/O 클래스들을 적극적으로 활용해야 한다. I/O Stream은 자바 I/O의 핵심 부분이다. 그리고 이런 로우 레벨의 개발에서는 매우 중요한 역할을 차지하기도 한다.
InputStream
InputStream은 바이트 기반 입력 스트림을 나타내는 추상 클래스다. 이는 데이터를 바이트로 읽어오는 역할을 한다. InputStream에서 제공하는 read() 메서드를 사용하여 바이트 데이터를 읽고, 스트림의 끝에 도달하면 -1을 반환한다. 주로 파일, 네트워크 연결 등에서 데이터를 읽을 때 사용된다. 이를 구현한 클래스는 FileInputStream, ByteArrayInputStream 등이 있다.
OutputStream
OutputStream은 바이트 기반 출력 스트림을 나타내는 추상 클래스다. 이는 데이터를 바이트로 쓰는 역할을 한다. OutputStream에서 제공하는 write() 메서드를 사용하여 바이트 데이터를 출력하고, 스트림의 끝에 도달하면 예외를 발생시킨다. 주로 파일, 네트워크 연결 등에서 데이터를 읽을 때 사용된다. 이를 구현한 클래스는 FileOutputStream, ByteArrayOutputStream 등이 있다.
BufferedReader
BufferedReader는 문자 기반 입력 스트림을 감싸는 클래스로, 버퍼링된 입력을 제공한다. 이는 문자열 데이터를 읽어오는 역할을 한다. BufferedReader에서 제공하는 readLine() 메서드를 사용하여 한 줄씩 문자열을 읽고, null을 반환하면 끝에 도달한 것이다. 이름처럼 효율적인 문자열 입력을 위해 버퍼링을 제공한다.
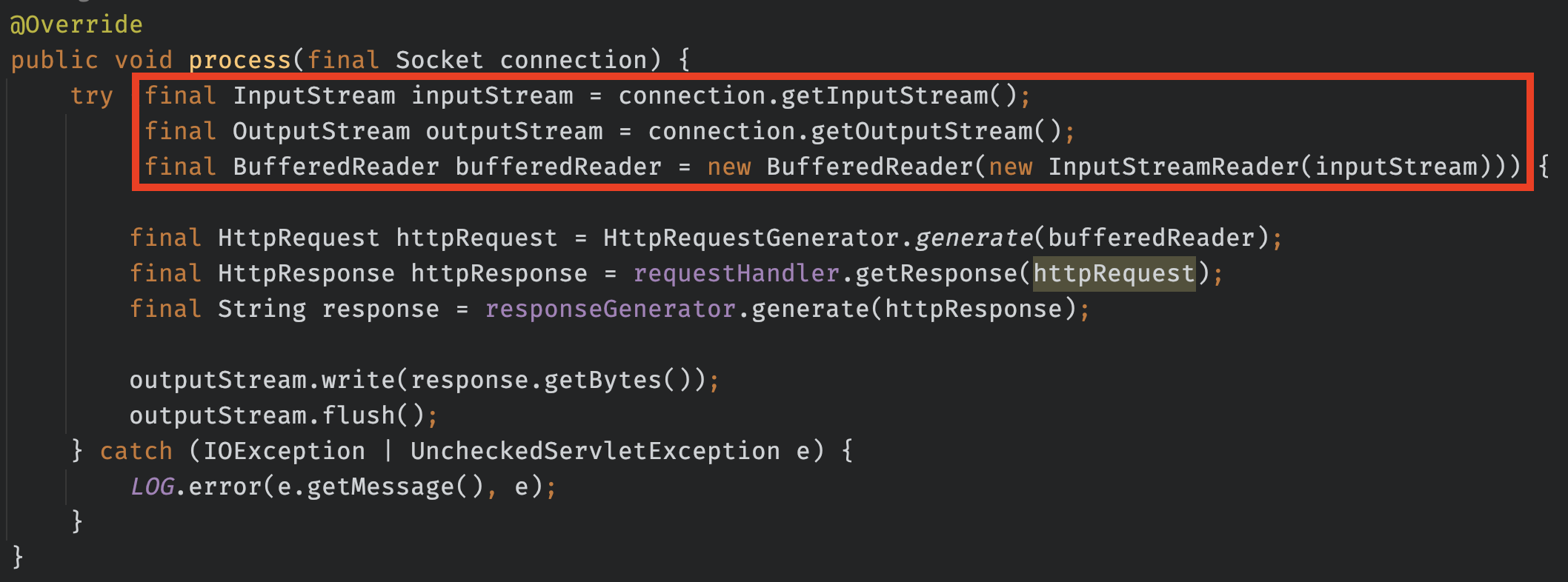
톰캣 프로세스를 구현할 때 I/O Stream과 바이트로 써진 데이터를 BufferedReader로 가져와 HttpRequestGenerator에서 한 번 더 변환 과정을 거치게 된다.

이렇게 BufferedReader에서는 header의 Content-Length만 알고 있다면 바이트로 이루어진 데이터를 문자열로 변경해 주는 기능을 제공한다.
톰캣이 사용하는 I/O Stream

위, 아래는 실제 톰캣 코드인데, 마찬가지로 Input,Output I/O를 사용하고 있다. 가만 보면 이상한 게 있다. 자바에서 기본적으로 제공하는 I/O Buffer가 아닌, 자체적으로 커스텀한 Http11I/OBuffer를 사용하고 있다는 것이다.

이렇게 자체적으로 재구현한 이유는 상당히 많은데, 간단하게 요약하면 다음과 같다.
- HTTP 표준 준수
- 톰캣은 HTTP 요청을 정확하게 처리하고 웹 애플리케이션에 전달하기 위해 HTTP 표준을 준수해야 한다. 뒤쪽에서 언급하겠지만, 톰캣은 널리 알려진 WAS이고, 스프링 부트의 내장 서버로 채택되기도 한 만큼 HTTP 표준과 RFC 9110 명세를 철저하게 지키려고 노력한다.
- 특정 요구 사항 처리
- 톰캣은 서블릿 컨테이너와 같은 특정한 요구 사항을 충족해야 한다. 이러한 요구 사항을 처리하기 위해서는 자체 InputBuffer로 HTTP 요청을 파싱하고 처리하는게 유지보수성이 좋다.
- 최적화 및 성능 향상
- 톰캣은 대량의 요청을 동시에 처리할 수 있어야 한다. 따라서 성능이 매우 중요한데, 자바에서 제공해주는 InputBuffer를 사용하면 들어오는 요청을 최적의 시간/공간 복잡도로 처리할 수 없다.
- 자체 개발 및 제어
- 다들 알다시피 톰캣은 오픈소스며, RFC나 새로운 명세에 대한 요구사항이나, 수정 사항을 자체적으로 반영할 수 있어야 한다.
지금 톰캣 구현 미션에서는 HTTP 표준과 RFC 명세를 명확히 만족하지는 못하기 때문에 자바에서 기본적으로 제공해주는 I/O Stream 클래스를 사용했다.
읽은 요청으로 Request 객체 구성하기
기본적으로 HttpRequest의 구조는 다음과 같다.

크게 Method, Path, Protocol, Headers로 나눠져있다. 앞의 I/O Stream 과정을 거치고 나면 헤더에서는 아래와 같은 값을 볼 수 있다. RequestLine의 정보들에 비해 매우 많은 비중을 차지한다.

종합해 보면 Request라는 객체를 구성하는 4개의 객체가 있으며, 각 객체에서 관리하는 값들과 처리해야 하는 부분들을 적절하게 분리해야 한다.

Method, Path, Version of the protocol은 RequestLine으로 묶어서 부르기도 한다. 따라서 필자는 아래와 같은 객체를 구성하게 되었다. Request의 최종 설계를 보면 다음과 같은 구조를 띄고 있다.

톰캣이 응답을 반환하는 법 (Feat. Servlet 동작 원리)
클라이언트의 요청을 정상적으로 Request 객체로 만들었다. 다음 단계는 HttpMethod가 GET 요청인지, POST 요청인지 구분하여 각각 doGet(), doPost() 메서드를 호출하는 것이다. 실제 Servlet 동작 방식은 다음과 같은 순서를 따른다.
- 클라이언트가 URL을 입력하면 HttpRequest를 Servlet Container로 전송한다.
- 요청을 전송받은 Servlet Container는 HttpServletRequest와 HttpServletResponse 객체를 생성한다.
- web.xml을 기반으로 사용자가 요청한 URL이 어느 서블릿에 대한 요청인지 찾는다.
- 해당 서블릿에서 service 메서드를 호출한 후 클라이언트의 HttpMethod에 따라 do + HttpMethod()를 호출한다.
- do + HttpMethod() 메서드는 동적 페이지를 생성한 후 HttpServletResponse 객체에 응답을 보낸다.
- 응답이 끝나면 HttpServletRequest, HttpServletResponse 두 객체를 소멸시킨다.
현재 3번까지는 구현된 상태이므로, 4번 과정을 진행해야한다. (현재 미션에서 Servlet 표준을 모두 준수하지는 않기 때문에 객체 소멸 단계는 진행하지 않는다.) HttpServlet 클래스에서 사용자 요청을 처리하는 doGet/Post 메서드는 모두 HttpServletRequest와 HttpServletResponse 객체를 파라미터로 가지고 있다.

즉, 실제 톰캣에서는 클라이언트의 요청과 응답을 파라미터로 모두 받는다. 하지만, 실제로 HttpServletResponse를 사용하는 곳은 예외를 던지는 정도로 그닥 많지 않다.
HttpServletResponse를 같이 넘겨주는 이유
그럼에도 HttpServletResponse를 파라미터로 같이 넘겨주는 이유는 HttpServletRequest를 체이닝된 필터들로 처리하기 때문이다. HttpServletRequest들이 해당 필터들을 순차적으로 검증하다가 어느 필터에서 실패했는지에 대한 정보를 같이 넘겨줘야한다.
만약 HttpServletResponse를 같이 넘겨주지 않는다면, 아래와 같은 문제가 발생할 수 있다.
- 필터마다 HttpServletResponse를 생성하는 로직이 필요하다.
- 이전 필터들에 대한 정보를 얻기 힘들다.

요청을 받으면 StandardWrapperValve 클래스의 invoke() 메서드가 호출된다. StandardWrapperValve 클래스는 서블릿을 구현하는 Wrapper 인터페이스의 표준 구현이다. 이 클래스를 통해 각 요청에 알맞는 서블릿 컨테이너를 할당하고 필터 체인을 사용한다.
다시 돌아와서 톰캣의 HttpServlet의 service는 다음과 같이 구성되어 있다. HttpServlet은 Abstract 클래스라 doGet, doPost, doPut..의 메서드는 추상 메서드로 제공한다.(구현은 HttpServlet을 상속하는 각 핸들러에서한다.)

아쉬운 점
이번 미션에서는 서블릿 표준을 따르는 기본 뼈대 코드가 있었다. 실제로 특정 path에 요청을 보내면 해당 path에 맞는 뷰를 반환해야 하기 때문에 HttpServlet이라는 네이밍 대신 AbsrtractController라는 네이밍으로 제공해주신 것 같다.
public interface Controller {
void service(HttpRequest request, HttpResponse response) throws Exception;
}public abstract class AbstractController implements Controller {
@Override
public void service(HttpRequest request, HttpResponse response) throws Exception {
// http method 분기문
}
protected void doPost(HttpRequest request, HttpResponse response) throws Exception { /* NOOP */ }
protected void doGet(HttpRequest request, HttpResponse response) throws Exception { /* NOOP */ }
}
또한, 서블릿 표준을 지키기 위한 뼈대 코드가 제공되었는데 이 부분은 좀 의아했다. 이번 미션에서는 필터 체인으로 요청을 처리할만큼 요구사항이 복잡하지는 않았다. 특히나 HttpResponse를 파라미터로 받으려면 얼마 되지도 않는 검증, 파싱 로직을 각 단계별로 setter로 붙여야한다.
미션중에 HttpResponse 지우지말라는 요구사항도 도착하기도 했다. 내가 볼 때는 기본적인 Http 요청만 처리하면 되었기 때문에 Response를 필요에 따라 만들어서 반환했다.

이게 잘 만든 코드인지는 모르겠는데, 요구사항을 만족하기 위해서 불편한 옷을 입는 것 보단 낫다고 생각한다.
구성한 Request 객체를 Response 객체로 반환하기
Response를 구성하려면 Request와 마찬가지로 구조를 먼저 파악해야 한다. Response 구조는 다음과 같다. 마찬가지로 RequestLine보다 RequestHeaders의 비중이 훨씬 많다.

특이하게도 Response는 문자열 자체로 반환하기 때문에 객체 자체로 반환할 수 없다. 그래서 반환에 필요한 정보들을 담고있지만, 헤더 구조와 완전히 똑같이 구성하지는 않았다.

Response가 실제로 반환될 때는 크게 RequestLine, Content-Type, Content-Length로 이루어지는데 Content-Length에는 html 파일, 관련 static 파일들이 같이 첨부되어 여러 번의 반환이 매우 부담되는 작업이 되기도 한다.


톰캣 기여하기
방대한 데이터들을 보니 갑자기 톰캣이 어떻게 데이터들을 원하는 형태로 파싱 하는지 궁금해져서 톰캣 내부 로직들을 뜯어봤다. 톰캣은 Content-Type을 추출하는 메서드가 Request 클래스 안에 존재한다.
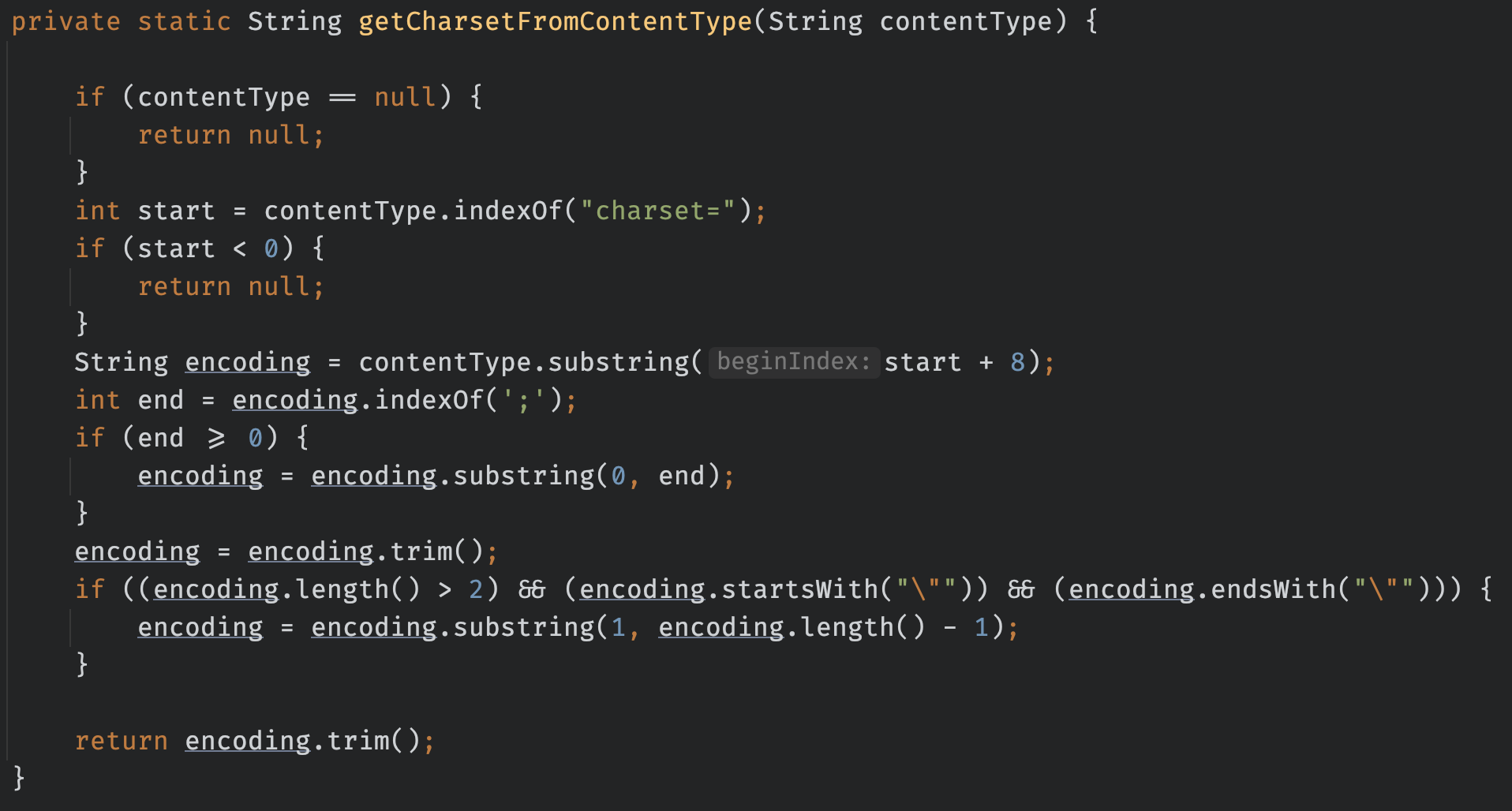
위 메서드는 Content-Type을 입력받으면 해당 값들을 적절하게 파싱 해서 반환해 주는 메서드다. 이걸 보고 처음 든 생각이 가독성이 너무 안 좋다는 것이었다. 위 메서드의 프로세스는 다음과 같다.
- contentType이 null인지 검사
- 문자열이 "charset="으로 시작하는지 검사
- 문자열에서 "charset=" 제거
- ;(세미콜론)으로 분리(separate)
- 만약 charset의 값이 여러개라면 세미콜론을 제거
- 문자열 앞 뒤 공백 제거
- 문자열의 길이가 2 이상이고, "(큰따옴표)로 시작하고 끝난다면 "(큰따옴표) 제거
- 문자열 앞 뒤 공백 제거 후 반환
실제로 위 메서드는 충분히 효율적으로 동작하기는 한다. 하지만 효율성은 효율성이고, 필자는 시간 복잡도는 그대로 가져가되 가독성을 증대시킬 수 있을 거라고 생각했다.

그리고 첫 번째 변경사항의 버전이 만들어졌다. 주요 변경사항은 분기문 조합, startsWith와 endWith 및 복잡한 연산자를 제거한 정도다. 하지만 이 코드에서는 가장 중요한 걸 고려하지 못했다.

간단하게 설명하면 리팩터링한 코드에는 다음과 같은 문제가 있다.
- RFC 9110 명세 만족하지 않음
- String.replaceAll()은 정규식을 사용하기 때문에 비용이 비쌈
원래 이렇게 많은 개발자들이 사용하는 오픈소스의 경우 머지를 대충 해주는 것 같지는 않다. 적어도 내가 고치거나 추가한 코드 때문에 문제가 발생하면 그것대로 너무 골치 아플 것 같다.
그렇기 때문에 충분히 closed 될 수 있는 변경사항이었다고 생각한다. 다만, 살펴본 결과 기존의 코드도 RFC 9110을 제대로 만족하고 있지는 않았기 때문에 톰캣 관리자분도 다음 요청에서 제대로 구현해 달라는 의미로 자세한 코멘트를 남겨주신 것 같다.
계속 RFC 9110이라는 이야기를 하고 있는데, 이 문서에서 제시하는 Media Type의 조건은 다음과 같다.
- media-type은 "/"의 하위 파라미터여야 한다.
- type은 토큰이어야 한다.
- 서브타입은 토큰이어야 한다.
- 파라미터가 키/값 쌍의 형태로 올 수 있어야 한다.
- 파라미터의 유무를 판단해야 한다.
- 파라미터 값은 파라미터 이름의 의미에 따라 대소문자를 구분할 수도 있고, 구분하지 않을 수도 있다.
- ...
자세한 내용은 여기를 참조하자.
자, 그럼 이 많은 조건들을 만족하는 메서드를 직접 만들어야 할까? 다행히도 o.a.t.u.http.parser.MediaType에 RFC 9110 요구사항을 모두 만족하도록 파싱 해주는 parseMediaType이라는 메서드가 존재했다. 두 번째 버전으로 변경된 코드는 다음과 같다.

MediaType을 사용한 코드를 보면서 곧 바로 궁금한 점이 생겼다.
- 기존 코드보다 좋은 효율을 자랑하는가?
- 예외 처리는 메서드 시그니처로 대신해도 되는가?
일단 1번에 대해서 곰곰히 생각해 봤는데, MediaType으로 파싱 하는 게 무조건 느리다. 정말 단순하게만 봐도 While문 + 분기문(n) 개는 더 늘었다. 심지어 원래 로직의 String.startsWith() 함수는 바이트단위로 쪼개서 계산한다.
다음으로 2번째 문제는 그 당시에는 어떻게 처리할지 감이 안왔다. 일단 메서드 시그니처로 처리하고 문제가 생기면 코멘트를 받아서 수정하기로 했다.
여기서 1번 문제에 대해 조금 더 고민해봐야 하는데, 기존 RFC 9110의 명세를 정확하게 지키는 게 중요할까? 아니면 아주 미세한 만큼의 시간이 늦는 게 나을까?
실제로 parseMediaType 메서드가 엄청나게 복잡하고 거대한 로직은 아니다. 그리고 톰캣은 WAS로 분류되는만큼 웹 표준을 잘 지켜야 한다고 생각했다.

그리고 2번째 리뷰 요청을 보냈는데, 예상했던대로 메서드 시그니처에 대한 코멘트가 왔다. I/OException을 메서드 시그니처에서 처리하면 컴파일 자체가 되지 않는다고 한다. 비슷한 상황에서 똑같은 예외를 던지는 클래스 힌트를 주셨다.

다른 코드를 보면 MediaType에서 던지는 예외를 삼키고, 아래에서 null 값에 대한 처리를 별도로 해준다. 실제로 IOException을 던지는 곳을 보면 "this isn't going to get logged anywhere"과 같은 문구가 적혀있기도 하다.

이렇게 메서드 시그니처를 없에고 IOException에 대한 톰캣 표준 예외처리까지 모두 완료한 후 마지막 PR을 제출했다. 4개의 빌드 및, 호환성 체크 등등의 검사를 마치고 머지가 되었다.

이렇게 톰캣을 직접 구현하면서 컨트리뷰트까지 해보았는데, 꽤나 재미있고 좋은 경험이었다. 무언갈 깊이 있게 학습하고 내 코드가 실제로 반영되는 것은 상상 이상으로 즐겁다. 다른 PR도 하나 있는데, 해당 PR은 중요한 null 체크 로직을 빼먹고 올려서 Based on PR로 커밋되었다. (다음 버전이 정식 릴리즈되면 내 코드를 스프링 상에서 볼 수 있겠지)
'Infrastructure' 카테고리의 다른 글
| [MSA] 장애 전파를 막기 위한 서킷브레이커 패턴 알아보기 (2) | 2023.11.10 |
|---|---|
| [Infra] 실행중인 도커, 젠킨스 컨테이너 타임존 변경하기 (3) | 2023.06.19 |
| [Infra] 서버 모니터링 구축기 [Docker, Prometheus, Grafana] (2) | 2023.06.06 |
| [Infra] CI/CD 파이프라인 구축기 [Jenkins, Docker] (5) | 2023.05.27 |
| [Infra] 팀원 모두에게 공통된 백엔드 환경 제공하기 [Docker-Compose, Dockerfile] (1) | 2023.05.06 |
