우아한테크코스 팀 프로젝트를 진행 중입니다. 5차 스프린트 요구사항들 중 아래와 같은 요구사항도 존재했는데요.
- 서비스에서 사용하는 쿼리를 정리하고, 각 쿼리에서 사용하는 인덱스 설정
- 서비스에서 사용하는 모든 조회 쿼리와 테이블에 설정한 인덱스 공유
- 인덱스를 설정할 수 없는 쿼리가 있는 경우, 인덱스를 설정할 수 없는 이유 공유
기존 쿼리를 만들 때 어느 정도 개선을 해오면서 만들었었기 때문에 평소 쿼리에 대한 고민을 많이 해보지도 않았었습니다. 실제로 쿼리 개선이 필요할 만큼 TPS가 높지도 않았고요. 또한 어떤 쿼리가 문제인지 찾아내는 과정을 위한 학습도 되어있지 않았습니다.
그래서 이번 글에서는 아무것도 모르는 상태에서 기존 쿼리를 어떻게 개선해 나갔는지 천천히 정리해나가 보도록 하겠습니다. 이번에 개선할 쿼리는 필터링 조회 쿼리입니다. 기본적으로 N+1 문제는 해결되어 있는 상태입니다.
필터링 조회 쿼리 개선 사항 살펴보기
집사의 고민 서비스의 필터링 기능을 보면 영양기준(standard), 주원료(primary_ingredient), 브랜드(brand), 기능성(functionality) 총 4개의 기준으로 필터링 기능을 제공합니다.

ERD
그렇다면 이 필터링 기능에 필요한 테이블들은 뭐가 있을까요? 다양한 테이블들이 이 기능에 관여하는데, 특징이라면 대부분 pet_food 테이블을 기점으로 관여합니다.

참고로 functionality, primary_ingredient 테이블은 pet_food 테이블과 ManyToMany 관계이기 때문에 중간에 매핑테이블이 있는 모습입니다.
네이티브 쿼리
아래 쿼리는 사용자가 다음과 같은 조건으로 필터링했을 때 동작하는 쿼리입니다. 페이지네이션은 오프셋(offset) 방식으로 동작하는게 아닌, 커서(cursor) 방식으로 동작합니다. 또한 필터링 조건마다 쿼리가 다르게 나가기 때문에 복잡한 경우의 수를 기준으로 쿼리 개선을 진행하겠습니다.
- 식품의 브랜드는 오리젠이어야 한다.
- 식품은 미국의 영양기준을 만족해야 한다.
- 식품의 주원료는 돼지고기여야 한다.
- 식품의 기능성은 튼튼이어야 한다.
- 페이지 카운트
select distinct pet_food.id,
pet_food.brand_id,
pet_food.created_at,
pet_food.eu_standard,
pet_food.us_standard,
pet_food.image_url,
pet_food.modified_at,
pet_food.name,
pet_food_primary_ingredient.pet_food_id,
pet_food_primary_ingredient.id,
pet_food_primary_ingredient.primary_ingredient_id,
pet_food.purchase_link
from pet_food pet_food
join
brand brand
on brand.id = pet_food.brand_id
join
pet_food_primary_ingredient pet_food_primary_ingredient
on pet_food.id = pet_food_primary_ingredient.pet_food_id
join
pet_food_functionality p3_0
on pet_food.id = p3_0.pet_food_id
where pet_food.id <= 929431
and brand.name = '오리젠'
and pet_food.us_standard = true
and exists(select 1
from pet_food_primary_ingredient sub_pet_food_priamry_ingredient
join
primary_ingredient sub_primary_ingredient
on sub_primary_ingredient.id = sub_pet_food_priamry_ingredient.primary_ingredient_id
where sub_primary_ingredient.name in ('돼지고기')
and pet_food.id = sub_pet_food_priamry_ingredient.pet_food_id)
and exists(select 1
from pet_food_functionality sub_pet_food_functionality
join
functionality functionality
on functionality.id = sub_pet_food_functionality.functionality_id
where functionality.name = '튼튼'
and pet_food.id = sub_pet_food_functionality.pet_food_id)
order by pet_food.id desc
limit 20;
위 쿼리는 실제로 API 응답 속도 기준 100만 건 기준 약 48초가 걸립니다. 기능이 필터링 + 동적 조회를 해야해서 그런 것도 있겠지만, 쿼리가 자체가 너무 길고, 복잡합니다. 하나하나 개선해 나가면서, 최종적으로는 쿼리가 어떻게 변했는지 살펴봅시다.

정말 모든 컬럼들이 필요할까?
우아콘 2020에서 보았던 내용 중 이동욱 님의 발표에서 Entity보다는 DTO를 우선적으로 사용해라 라는 내용이 있습니다. 그 내용들 중에서는 조회 컬럼 최소화라는 내용도 존재합니다.
하지만 현재 쿼리는 pet_food 테이블의 모든 정보를 반환합니다. 반면, pet_food_primary_ingredient는 매핑 테이블이기 때문에 모든 컬럼에 대해서 인덱스가 적용되어 있긴 하지만, 필요하지 않은 컬럼이라면 과감히 제거하는 게 좋겠습니다.
엔티티 대신 DTO를 반환하게 된다면 조회 컬럼 제거 및 페치조인을 사용하기 위해 사용했던 불필요한 조인들도 없앨 수 있을 것 같습니다. 이를 개선한 부분은 다음 글에서 자세히 다룹니다.
실전 쿼리 개선(컬럼 제거) 보러 가기
쿼리 분석
위에서 개선한 쿼리(조회 컬럼 제거, 불필요한 조인 제거)가 현재 최적의 쿼리로 조회되고 있는지 살펴봐야 합니다. 아래는 쿼리 실행 계획의 일부입니다.

쿼리는 효율적으로 동작하고 있었는가?
과연 기존 쿼리는 효율적으로 동작하고 있던 것이었을까요? 하나씩 살펴보겠습니다.
간혹 type 컬럼에서 Index(인덱스 풀 스캔)과 Extra 컬럼의 Using Index(커버링 인덱스)를 헷갈리는 경우가 있는데, 덜 효율적인 것(Index)과 굉장히 효율적인 것(Using Index)입니다.
Sort - Using temporary; Using filesort
우선 커버링 인덱스를 타고 있는 테이블들을 기준으로 먼저 살펴보겠습니다. 커버링 인덱스란 쿼리를 실행하는데 필요한 모든 컬럼을 인덱스로만 처리할 수 있는 인덱스를 뜻합니다. 인덱스는 B-Tree 스캔만으로 원하는 데이터를 가져올 수 있으며, 컬럼을 읽기 위해 실제 데이터에 접근할 필요가 없기 때문에 매우 빠른 조회 속도를 자랑합니다.

Brand 테이블 Extra에 "Using temporary; Using filesort" 키워드가 있는 모습입니다. Using temporary와 Using filesort를 알기 위해선, MySQL의 옵티마이저 실행 계획을 알아야 합니다.
Using Temporary(임시 테이블)
"Using Temporary"를 한국어로 번역하면 "임시 사용"이라는 뜻입니다. MySQL 엔진은 스토리지 엔진으로부터 받아온 레코드를 정렬 또는 그룹핑할 때는 내부에서 임시 테이블을 만들어 사용합니다.
MySQL 엔진이 사용하는 임시 테이블은 처음에 메모리에 생성했다가 테이블의 크기가 메모리에 담을 수 없을만큼 커지면 디스크로 옮겨집니다.
원본 테이블의 스토리지 엔진과 관계없이 임시 테이블이 메모리를 사용할 때는 Memory 스토리지 엔진을 사용합니다. 아래는 MySQL 엔진이 임시 테이블이 만드는 조건들입니다.
- ORDER BY와 GROUP BY에 명시된 컬럼이 다른 쿼리
- ORDER BY나 GROUP BY에 명시된 컬럼이 조인의 순서상 첫 번째 테이블이 아닌 쿼리
- DISTINCT와 ORDER BY가 동시에 존재하는 경우
- DISTINCT가 인덱스로 처리되지 못하는 쿼리
- UNION이나 UNION DISTINCT가 사용된 쿼리
- UNION ALL이 사용된 쿼리
- 쿼리 실행 계획의 select_type이 DRIVED인 쿼리
위 7가지 경우 중 1~4번째 경우는 Extra 컬럼에 "Using Temporary"가 표시됩니다. 반면 5~7번째 경우에는 Extra 컬럼에 "Using Temporary"가 표시되지는 않지만, 임시 테이블이 사용되긴 합니다.
select distinct pet_food.id,
pet_food.name,
brand.name,
pet_food.image_url
from pet_food inner join brand on brand.id = pet_food.brand_id
where brand.name = '오리젠'
...
order by pet_food.id desc
limit 20;
위에서 말했듯이 임시 테이블의 크기가 너무 커져 메모리에 담지 못할 정도의 크기라면 성능 이슈에 각별히 주의해야 합니다. 아래는 임시 테이블이 디스크에 생성되었는지 알 수 있는 명령어입니다.
SHOW SESSION STATUS LIKE 'Create_tmp%';

디스크에 임시 테이블이 생성되지는 않은 모습입니다. 아직까지 디스크에 기록할 만큼 많은 데이터 수를 가진 것도 아니어서 개선할 사항은 크게 없어 보입니다.
또한 쿼리 상에서도 큰 변경사항은 없었습니다. distinct를 붙여 놓은 이유는 카테시안 곱을 방지하기 위해서였습니다. 하지만 Hibernate 6부터는 자동 중복 제거를 해주니 지우고 넘어가겠습니다.
Using filesort(정렬)
MySQL의 정렬 처리는 크게 2가지로 나뉩니다.
- Index를 이용한 정렬
- MySQL 서버에서 정렬하는 방법 (File Sort)
인덱스를 사용할 수 있는 경우는 아래의 경우입니다.
- ORDER BY에 명시된 컬럼이 제일 먼저 읽는 테이블에 속해야 한다.
- ORDER BY 절의 순서가 인덱스와 일치해야 한다.
- WHERE 절에 첫 번째 읽는 테이블에 대한 조건이 있다면, ORDER BY 절도 같은 인덱스를 사용할 수 있어야 한다.
인덱스를 사용하는 정렬은 완벽한 조건을 요구하는 만큼 처리가 빠릅니다. 인덱스는 애초에 값이 정렬되어 있기 때문에 해당 인덱스를 읽기만 하면 되기 때문이죠.
하지만 인덱스를 사용할 수 없다면 Filesort를 이용합니다. 기존 코드에서도 임시 테이블을 사용하여 Filesort를 진행한 모습이었죠. Filesort는 정렬 할 레코드가 많아질수록 쿼리의 응답 속도가 현저히 떨어지게 됩니다.
Filesort를 사용하는 경우도 2가지로 나눌 수 있는데, 다음과 같습니다.
- 드라이빙 테이블만 정렬("Using filesort")
- 임시 테이블을 이용한 정렬("Using temporary, Using filesort")
드라이빙 테이블만 정렬되는 방식은 조회하는 테이블 중 먼저 액세스 되는 테이블만 SortBuffer에서 정렬하여 나머지 테이블들과 조합하는 방식입니다.

이 경우 드라이빙 테이블을 우선적으로 정렬해야하기 때문에 SortBuffer로 테이블 하나를 옮겨서 정렬하는 작업이 필요합니다. 드라이빙 테이블만 정렬하는 방법을 사용할 수 없다면 임시 테이블을 사용해야 하는데, 임시 테이블을 이용한 정렬은 반대로 드라이빙 테이블과 드리븐 테이블을 조인한 다음 그 결과를 전부 임시테이블에 넣어서 정렬하는 방식입니다.

이 방법은 모든 컬럼들을 임시 테이블에 넣고 정렬을 수행하므로 가장 느립니다. 또한 레코드가 많아지면, 임시 테이블이 디스크에 저장되면서 I/O 부하가 발생할 수도 있습니다. 하지만 위에서 확인했듯이 아직 임시 테이블에 저장될 데이터 수는 아닙니다.
Using filesort를 개선하려면
하지만 Using Filesort 역시 개선하지 않았습니다. 그 이유는 Join 방식에 있습니다. MySQL은 FROM절에 명시된 테이블 순서대로 드라이빙 테이블을 선정하지 않고, 옵티마이저가 상황에 따라서 최적의 테이블을 드라이빙 테이블로 선정합니다. 즉, 개발자가 드라이빙 테이블을 예측하기 힘들다는 것입니다.
Left Join 사용하기
이 문제를 해결하기 위해서는 2가지 방법이 있습니다. 첫 번째 방법은 Left Join을 사용하는 방법입니다. Left Join을 사용하게 되면 MySQL의 옵티마이저가 드라이빙 테이블을 처음 지정한 테이블(왼쪽 테이블)로 지정하기 때문에 B-Tree 인덱스 순서대로 읽기가 가능해집니다.
현재 쿼리에서 Inner Join을 사용하는 부분은 총 3곳입니다.
- pet_food -> brand
- pet_food_functionality -> functionality
- pet_food_primary_ingredient -> primary_ingredient
하지만, 위 join들을 Left Join으로 변경하게 된다면 드리븐 테이블의 커버링 인덱스를 만족하지 못하는 문제점이 생깁니다. 드라이빙 테이블은 모든 데이터가 존재할 테지만, 드리븐 테이블에서 가져온 데이터들은 null 값일 수도 있을 테니까요.
그래서 MySQL은 드리븐 테이블에서 가져온 데이터가 null인지 아닌지를 판단하는 별도의 처리를 한 번 더 하게 되며, 해당 테이블을 커버링 인덱스로 처리할 수 없게 됩니다.
그리고 하나의 문제가 더 있습니다. 드리븐 테이블의 데이터 수가 드라이빙 테이블의 데이터 수 보다 더 적을 때입니다. 예를 들어 드라이빙 테이블의 데이터는 1억 개이고, 드리븐 테이블의 데이터는 1개라면 결과는 1억 개가 조회될 것입니다. 하지만 Inner Join을 사용하면 pk와 fk가 일치하는 단 한 개의 레코드만 조회할 수 있게 됩니다.
Straight Join 사용하기
두 번째 방법은 Straight_Join을 사용하는 방법입니다. Straight_Join은 말 그대로 선언한 순서대로 드라이빙 테이블을 지정합니다. 개발자가 직접 드라이빙 테이블을 지정할 수 있다는 것이죠.
하지만, Straight_Join은 ANSI SQL이 아니기 때문에 여러 ORM에서 공식적으로 제공하지 않을 확률이 높습니다. 집고 프로젝트는 JPA와 복잡한 쿼리에 한해서는 Querydsl을 사용하는데, Hibernate 역시 Straight_Join 문법을 지원하지 않기 때문에 깔끔히 포기했습니다.
만약 JPA에서 Straight_Join을 사용하고 싶다면 네이티브 쿼리(native query)를 사용해야 합니다. 아래는 Using temporary; Using filesort를 살펴보며 개선한 쿼리입니다.
select pet_food.id,
pet_food.name,
brand.name,
pet_food.image_url
from pet_food
inner join brand on brand.id = pet_food.brand_id
where brand.name = '오리젠'
and pet_food.us_standard = 'true'
and exists(select 1
from pet_food_primary_ingredient
join
primary_ingredient
on primary_ingredient.id = pet_food_primary_ingredient.primary_ingredient_id
where pet_food.id = pet_food_primary_ingredient.pet_food_id
and primary_ingredient.name = '돼지고기')
and exists(select 1
from pet_food_functionality
join
functionality
on functionality.id = pet_food_functionality.functionality_id
where pet_food.id = pet_food_functionality.pet_food_id
and functionality.name = '튼튼')
order by pet_food.id desc
limit 20;
여전히 느린 쿼리
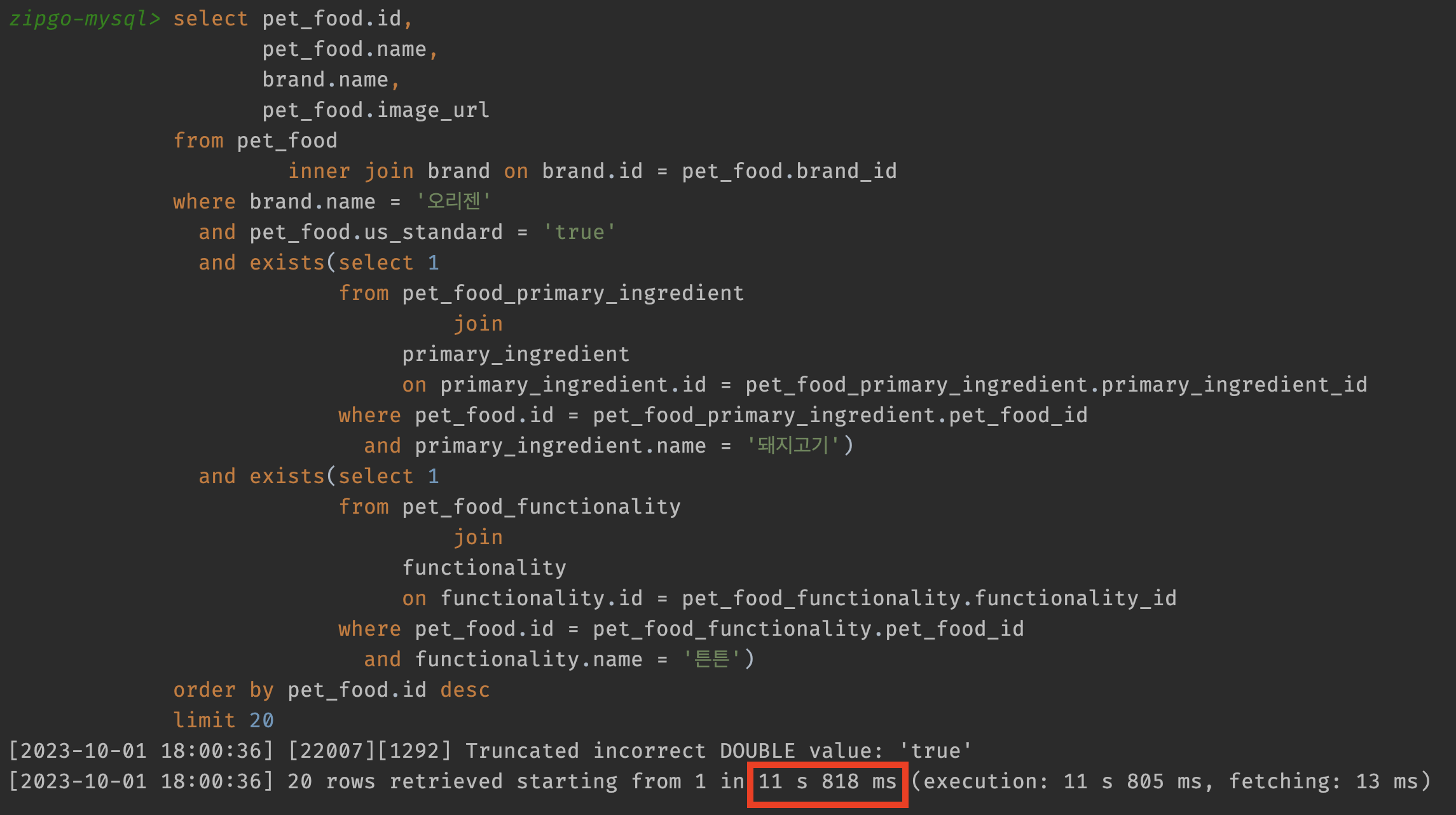
이때까지 간단하게 개선한 내용과 현재 커버링 인덱스가 적용된 테이블들의 분석을 마치고 쿼리를 실행해 보았습니다. 보시다시피 약 11.8s의 느린 응답 시간을 가지고 있습니다. 쿼리가 왜 이렇게 느린 걸까요? 저는 쿼리의 실행 계획에 답이 있다고 생각했습니다. 다시 실행계획을 살펴보겠습니다.

커버링 인덱스를 사용하지 못하고 있는 테이블은 총 3개가 있지만, 그중에서 pet_food_primary_ingredient 테이블의 rows 컬럼을 눈여겨봐야 합니다. 여기서 우리는 이 결과를 2가지 시선으로 바라볼 수 있습니다.
많은 Row를 읽어야 하는 옵티마이저
다른 테이블들과의 큰 차이점은 rows가 90만이 넘는다는 것입니다. 실제로 매핑 테이블의 조건절에서 사용하는 주원료(primary_ingredient) 데이터(돼지고기)의 수는 약 66만 개입니다.

이는 옵티마이저가 필요 이상의 데이터를 읽고 있다고 볼 수 있습니다. 하지만 옵티마이저가 해당 데이터를 더 읽는 이유는 찾지 못했습니다. 심지어 위 사진에 보이는 쿼리의 실행계획의 rows도 93만 개였습니다.
rows 수를 보고 90만이라는 숫자 자체가 잘못된 게 아니라는 판단을 내렸습니다. 왜냐하면 pet_food_primary_ingredient의 총 데이터 개수는 200만 개이기 때문에 옵티마이저가 충분히 필터링하고 있다고 느꼈기 때문입니다.
rows의 수는 테이블 구조가 바뀌거나 비즈니스로 인한 필터링 쿼리가 바뀌지 않는 이상 더 줄일 수 없다는 판단을 내린 상태로 개선을 진행했습니다.
90만 Rows를 커버링 인덱스로
90만 rows가 이상한 게 아니라면 뭐가 이상한 걸까요? 피할 수 없다면 즐기라는 말이 있듯이 결국 옵티마이저가 90만 rows를 읽어야 한다면, 부분 인덱스가 아닌 커버링 인덱스를 태우는 게 좋을 거라는 생각이 들었습니다.
여기서 궁금증이 하나 더 생깁니다. "기존 매핑 테이블의 컬럼 3개(pk, fk, fk)가 모두 인덱스인데, 어째서 커버링 인덱스가 안타져 있는 거죠?"라고 말이죠. 이는 단지 옵티마이저의 선택에 따라 달라집니다. 이 경우 쿼리의 테이블당 하나의 인덱스가 사용되었습니다.
즉, 옵티마이저는 차선책을 찾아줄 뿐이지 해결책은 아니라고 볼 수 있습니다. 그래서 실행 계획을 분석해서 옵티마이저가 쿼리를 최적으로 실행하고 있는지를 판단하는 게 개발자의 역할입니다.
복합 인덱스
옵티마이저가 인덱스 컬럼이 2개임에도 불구하고 하나의 인덱스만 사용하였습니다.
저는 이 문제를 복합 인덱스(Composite Index)로 해결했습니다. pet_food_id와 primary_ingredient_id를 하나의 인덱스로 묶어버리는 것이죠. 그럼 매핑 테이블에서 2개의 fk가 하나의 인덱스인 것처럼 동작하기 때문에 커버링 인덱스로 조회할 수 있게 됩니다.
복합 인덱스를 사용하는 데는 각별히 유의해야 할 점이 있습니다. 기본적으로 많은 분들은 복합 인덱스의 순서에 대해서 들어보셨을 겁니다. 보통 카디널리티가 높은 컬럼을 먼저 선언하라고 말이죠.
제가 복합 인덱스를 며칠 동안 열심히 쿼리를 실행해 본 결과 이 말은 반은 맞고 반은 틀린 말이라는 생각이 들었습니다. 당연히 중복도가 낮은 컬럼을 먼저 선언하는게 좋지 않냐?라고 생각하실 수도 있겠습니다.
물론 카디널리티가 높은 컬럼을 먼저 선언하는 건 "이론적으로" 맞는 말입니다. 다음 조건문에서 경우의 수를 최대한 배제할 수 있으니까요. 다시 쿼리를 살펴보겠습니다.

저희가 서브 쿼리에서 매핑 테이블의 인덱스 컬럼을 사용하는 조건절은 2개입니다. 여기서 중요한건 "순서"입니다. 당연히 join이 먼저 실행되고 where절이 실행되겠죠? 그런데 여기서 카디널리티가 높은 컬럼을 먼저 선언하면 어떻게 될까요?

조건은 카디널리티가 낮은 것이 먼저 걸려있지만, 복합 인덱스는 카디널리티가 높은 컬럼이 먼저 걸려있기 때문에 옵티마이저가 읽어야 하는 rows의 수가 늘어날 것입니다. 복합인덱스의 첫 번째 인덱스가 필요한 인덱스가 아니기 때문에 2번째 인덱스까지 읽어야 하기 때문이죠.
반대로 복합 인덱스 말고 쿼리의 순서를 바꾸면 되지 않냐?라고 질문할 수도 있지만, pet_food의 데이터 수는 100만, pet_food_primary_ingredient(매핑 테이블)의 데이터 수는 200만, primary_ingredient의 데이터 수는 단 3개 입니다.
그렇다면 pet_food와 pet_food_primary_ingredient를 조인하는 것 보다 primary_ingredient를 조인하는게 훨씬 더 적은 데이터로 연산이 가능합니다. 때문에 단지 복합인덱스 순서를 바꾸는 것보다 인덱스를 사용하더라도 옵티마이저가 계산할 로우수를 최대한 줄여주는 게 더 중요하다는 생각이 드네요.
실전 쿼리 개선(복합 인덱스) 보러 가기
이번 글에서는 이론적으로 쿼리와 데이터를 어떻게 개선할 수 있을지 다뤄보았습니다. 다음 글에서는 이 글을 바탕으로 실제로 적용하고 개선 전/후를 비교해 보도록 하겠습니다. 긴 글 읽어주셔서 감사합니다!
'성능 개선' 카테고리의 다른 글
| [Performance] 서드파티 API를 사용할 때 고려할 수 있는 최선의 방법들 (2) | 2023.10.08 |
|---|---|
| [DB] 실전! 집고의 쿼리 성능 개선기 (2) | 2023.10.02 |
| [Performance] nGrinder를 이용한 서비스 성능 측정 (3) | 2023.09.09 |
