문제 상황
프로젝트를 진행하면서 외부 API를 사용해야 하는 기능이 있습니다. 해당 API는 깃허브에서 PR(Pull Request의 List)를 조회하는 API입니다. 해당 API는 페이지네이션을 통해 접근해야 하는데요. 공식 문서를 살펴보면 한 번에 최대 100개의 PR만 가져올 수 있습니다.

사실 PR을 모두 조회할 필요는 없었습니다. 요구사항 특성상 많아봤자 한 번에 4~5개 정도의 PR만 조회하면 되었거든요. 하지만 무료 API를 제공하는 서드파티 입장에서도 그렇게까지 구체적인 API를 제공해주지는 않더라고요. 그리고 제공할 책임 또한 없습니다.
그렇다면 사용하는 입장에서는 할 수 없이 모든 PR들을 조회하고, 해당 PR들을 애플리케이션에서 가공해야겠죠. 이 때 PR의 개수가 총 300개라면 최소 3번의 요청을 보내게 됩니다. 그럼 비일비재하게 100개씩 여러 번 요청할 수밖에 없게 됩니다.
"에이~ API 몇 번 호출한다고 몇 초나 기다리겠어?"라고 생각하실 수도 있지만 PR 480개 기준 API 응답 속도가 떡하니 20초가 넘어버린 모습을 보실 수 있습니다. 단순 계산시 최소 5번의 요청을 보내야 하니 요청당 약 4초의 레이턴시를 가지게 되는 것이죠.
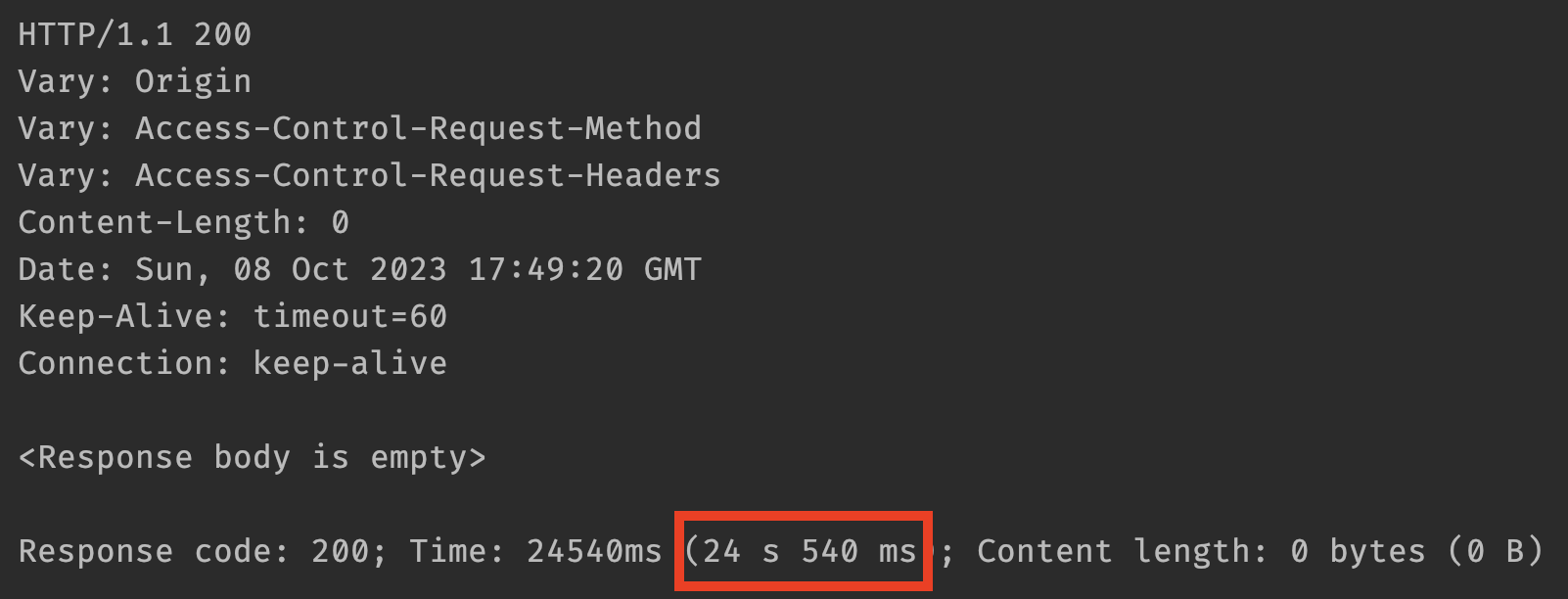
스케쥴러나 배치작업 같이 유저가 굳이 기다릴 필요가 없는 작업이면 몰라도, 해당 API는 사용자가 어떠한 값을 바로 보기 위해 직접 요청하는 API이기 때문에 20초나 기다리게 할 수는 없었습니다.
어떻게 해결할까?
그렇다면 저희의 손을 벗어난 영역에 대한 개선은 어떻게 해야할까요? 당연히 서드파티가 데이터베이스에서 데이터를 조회하는 시간은 저희의 영역이 아니지만, 요청을 보내는 단계까지는 서비스 개발자의 역할입니다.
우선 첫 번째로 병렬 처리입니다. RestTemplate은 모든 API를 동기적으로 호출합니다. 그렇기 때문에 위 예시에서는 5번의 요청을 동기 처리를 해서 최악의 상황에는 20초가 넘는 레이턴시를 가지게 된 것이죠.
병렬(Parallel) 처리
@Override
public List<GithubPrInfoResponse> getPrsByRepoName(final String accessToken, final String repo) {
final List<GithubPrInfoResponse> responses = new ArrayList<>();
final List<String> getPrsRequestUrls = new ArrayList<>();
for (int page = 1; page <= 5; page++) {
getPrsRequestUrls.add(getListPullRequestUrl(repo, page));
}
getPrsRequestUrls.parallelStream()
.forEach(url -> {
List<GithubPrInfoResponse> githubPrInfoResponses = fetchPrs(accessToken, url);
responses.addAll(githubPrInfoResponses);
});
return responses;
}
private List<GithubPrInfoResponse> fetchPrs(final String accessToken, final String url) {
final HttpHeaders headers = new HttpHeaders();
headers.setBearerAuth(accessToken);
final HttpEntity<Void> request = new HttpEntity<>(headers);
return restTemplate.exchange(
url,
GET,
request,
new ParameterizedTypeReference<List<GithubPrInfoResponse>>() {}
).getBody();
}

요청을 병렬 처리 하니 응답 시간이 4배 정도 줄었습니다. 아직까지 느리긴 하지만 그래도 API 응답속도 면에서는 꽤 유의미한 개선이라고 볼 수 있을 것 같습니다. 하지만 병렬 처리에는 한 가지 주의해야 할 점이 있습니다.
병렬 처리는 항상 빠를까?
병렬처리는 항상 빠를까요? 꼭 그렇지만은 않습니다. 병렬 처리에 영향을 미치는 요인들이 있기 때문인데요. 다음과 같은 환경을 고려하여 잘 맞는 방법을 선택해야 합니다.
- 데이터 수와 데이터당 처리 시간
- 병렬 처리는 스레드 풀 생성, 스레드 생성이라는 추가적인 비용이 발생하기 때문에 컬렉션에 데이터 수가 적고 데이터 처리 시간이 짧으면 순차 처리가 병렬 처리보다 빠를 수 있습니다.
- 코어(Core)의 수
- 싱글 코어 CPU의 경우 순차 처리가 빠릅니다. 병렬 처리를 할 경우 스레드의 수만 증가하고 번갈아 가면서 스케쥴링을 해야하기 때문에 순차 처리보다 오히려 낮은 성능을 보여주게 됩니다.
병렬 처리는 멀티 스레드 환경에서 스레드(Thread)가 아닌 코어(Core)들로 스레드를 병렬적으로 실행하는 것이라는 걸 꼭 명심해야합니다. 제 로컬 PC의 CPU는 Apple M1 Pro입니다. 잠깐 해당 CPU의 사양을 살펴볼까요?

제 로컬의 CPU 코어 수는 10코어라고 하네요. 다만 문제는 실제로 배포할 서버의 사양입니다. 만약 배포할 서버의 CPU 코어가 싱글 코어라면 병렬 처리에 대해서 다시 고민해봐야 합니다.
병렬 처리 다시 고민해보기
필자는 AWS 프리티어의 t4g.small 인스턴스로 배포를 진행하며 해당 서버의 CPU는 2코어입니다. 그럼 한 번에 여러개의 데이터를 처리하는 메서드를 병렬로 처리했을 때 스레드가 어떻게 배분되고 실행시간은 어떻게 나오는지 살펴보겠습니다.
public class Test {
@org.junit.jupiter.api.Test
public void test() {
long startTime = System.currentTimeMillis();
System.out.println("Execute Method Thread = " + Thread.currentThread());
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 20; i++) {
list.add(i);
}
list.parallelStream()
.forEach(number -> {
String threadName = Thread.currentThread().getName();
System.out.println("ThreadName In ParallelStream = " + threadName);
try {
Thread.sleep(5000);
} catch (InterruptedException e) { }
});
long endTime = System.currentTimeMillis();
long executionTime = endTime - startTime;
System.out.println("Method Execution Time: " + executionTime/1000 + "s");
}
}
위 코드는 한 번에 20개의 요청을 병렬처리 하는 메서드입니다. 병렬 처리 시 모두 다른 스레드를 사용하고 List 안에 있는 데이터 20개가 모두 한 번에 실행되고 마지막 5초만 기다리면 되겠죠?

하지만 결과는 저희의 예상과 다르게 나왔습니다. 시간도 2배나 걸렸고 무엇보다 서로 다른 스레드가 10개 밖에 되지 않습니다. 그 이유는 Parallel Stream의 구조 때문입니다. Parallel Stream은 내부적으로 ForkJoinPool이라는 스레드 풀을 사용하는데, 코어 하나당 하나의 thread를 생성할 수 있습니다.
그렇기 때문에 제 로컬 PC에서도 한 번에 최대 10개의 요청밖에 처리하지 못합니다. 그럼 EC2는 한 번에 2개의 처리만 할 수 있겠죠? 그럼 EC2에서는 코어 수가 1/5이니 위 로직이 수행되는 시간은 5배가 늘어 50초가 걸리게 될 것입니다.
서버의 사양이 좋아지면 당연히 부가적인 성능들도 좋아지겠지만, 특히 병렬 프로그래밍은 사용자가 늘어날수록 하드웨어의 사양에 많은 영향을 받습니다. 이런 이유 때문에 실무에서 대용량 트래픽을 감당할 때 병렬 프로그래밍 대신 ASync와 Non-blocking을 위주로 사용할 것 같습니다.(이건 제 생각이었습니다..)
비동기(Async) 처리
병렬 처리를 제외하고 외부 API를 호출하는 시간 자체를 단축할 수 있는 방법을 찾다 보니 WebClient를 알게 되었습니다. WebClient 외에도 CompletableFuture나 Runnable과 같은 인터페이스도 존재합니다.
WebClient
기존에 사용하고 있던 RestTemplate은 Spring 5.0부터 유지보수 모드라고 명시되어 있습니다. 실제로 Spring Framework 공식 문서에서는 WebClient를 사용하라고 권장하고 있기도 합니다.
팩트 체크 - RestTemplate은 정말 Deprecated 될까?
RestTemplate은 5.0부터 유지보수 모드(maintenance mode)를 유지하고 있습니다. 유지보수 모드란 스프링 버전을 업그레이드해도 버그 또는 보안 문제가 아닌 이상 해당 모듈에 기능을 추가하지 않는 상태입니다.
유지보수 모드로 바꾼 이유는 해당 모듈보다 좋은 기능을 가진 모듈을 만들었지만 하위 호환성을 지원하기 위해 남겨둔 것 같네요. 현재 Spring Framework 6.x 버전에도 유지보수 모드를 유지 중입니다. 때문에 곧 deprecated 된다는 루머 때문에 WebClient로 변경할 필요는 없습니다. deprecated 어노테이션이 붙을 때까지는 말이죠.
WebClient를 더 자세히 알아보겠습니다. 스프링 프레임워크의 공식 문서에서는 WebClient를 다음과 같이 소개합니다.
- Spring Framework 5.0부터 지원
- Http 요청을 수행하는 non-blocking 클라이언트
- 인터페이스이므로 create(), create(String), builder()를 사용해 객체 생성
조금 더 보기 쉽게 표로 살펴보겠습니다.
| RestTemplate | WebClient | |
| 지원 버전 | Spring Framework 3.0부터 지원 | Spring Framework 5.0부터 지원 |
| 처리 방식 | syncronize(동기) | non-blocking |
| 구현체 | 기본 HTTP 라이브러리 | 인터페이스 직접 구현 |
Non-blocking 처리로 개선
다만 WebClient는 Spring WebFlux 모듈의 클래스이기 때문에 Spring WebFlux 의존성을 추가해줘야 한다는 게 단점인 것 같습니다. 이 글에서 WebClient의 자세한 사용법이나 가이드는 제공하지 않습니다.
기존 로직
기존 GithubClient에서 List Pull Requests를 조회하는 로직은 다음과 같은 흐름이었습니다.

n번 째 페이지를 조회하고 해당 결과의 반환값이 있다면 다음페이지 조회, 없다면 호출을 종료합니다. 이는 동기 처리 방식에서는 잘 동작할 수 있는 로직입니다. 깃허브에 인증된 사용자 기준 API를 시간당 최대 5,000번 요청할 수 있지만 위 로직 그대로 non-blocking을 적용한 상태에서는 1초도 안돼서 모든 요청 횟수를 다 사용하게 되겠죠.
수정한 로직
로직을 재구성해보겠습니다. 해당 기능은 우아한테크코스의 크루들의 PR들을 대상으로 합니다. 한 기수의 어떠한 포지션(BE, FE..) 하나의 레파지토리에 동시에 올리는 최대 PR의 수는 다음과 같습니다.
포지션마다 다른 레파지토리를 사용하기 때문에 가장 크루 수가 많은 포지션(백엔드 기준 약 100명) * 미션의 최대 step 수(4단계) 미션 당 최대 400개의 PR이라는 결론을 도출할 수 있습니다.
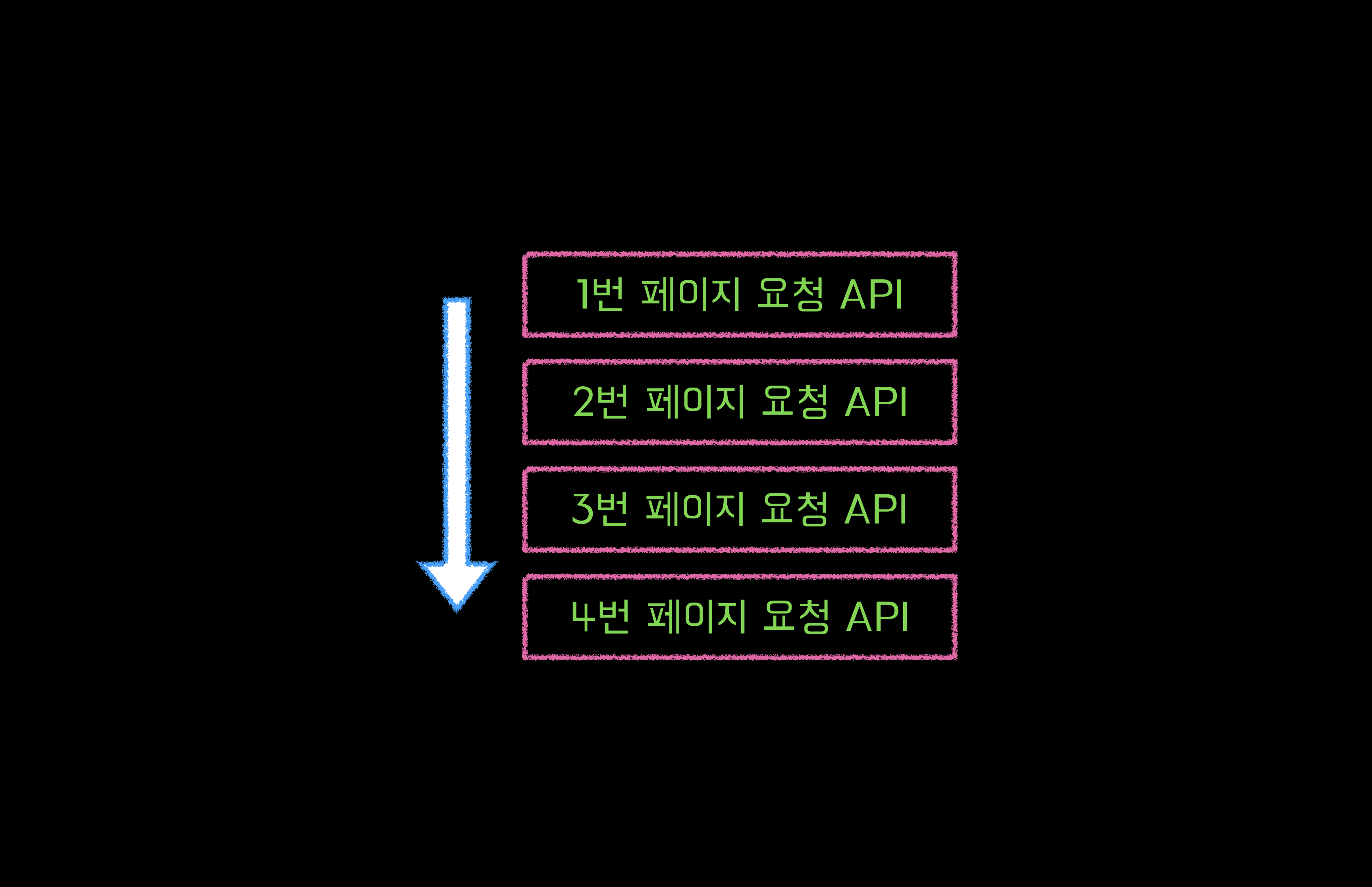
그러면 페이지를 총 4번 조회하면 되겠네요.(한 번당 PR 100개) 완벽한 병렬 실행은 아니지만 최대 응답 지연시간은 4개의 요청 중 가장 느린 응답 시간이라고 봐도 무방합니다. 그럼 WebClient로 변경한 뒤의 속도는 얼마나 개선되었을지 살펴봅시다.
public List<GithubPrInfoResponse> getPrsByRepoName(final String accessToken, final String repo) {
final List<GithubPrInfoResponse> responses = new ArrayList<>();
final List<String> prRequestUrls = createPrApiRequestUrls(repo, 4);
Flux.fromIterable(prRequestUrls)
.flatMap(url -> fetchPrs(accessToken, url))
.collectList()
.block()
.forEach(githubPrInfoResponses -> responses.addAll(githubPrInfoResponses));
return responses;
}
private Flux<List<GithubPrInfoResponse>> fetchPrs(final String accessToken, final String requestUrl) {
return webClient.get()
.uri(requestUrl)
.headers(headers -> headers.setBearerAuth(accessToken))
.retrieve()
.bodyToFlux(GithubPrInfoResponse.class)
.collectList()
.flux();
}
...
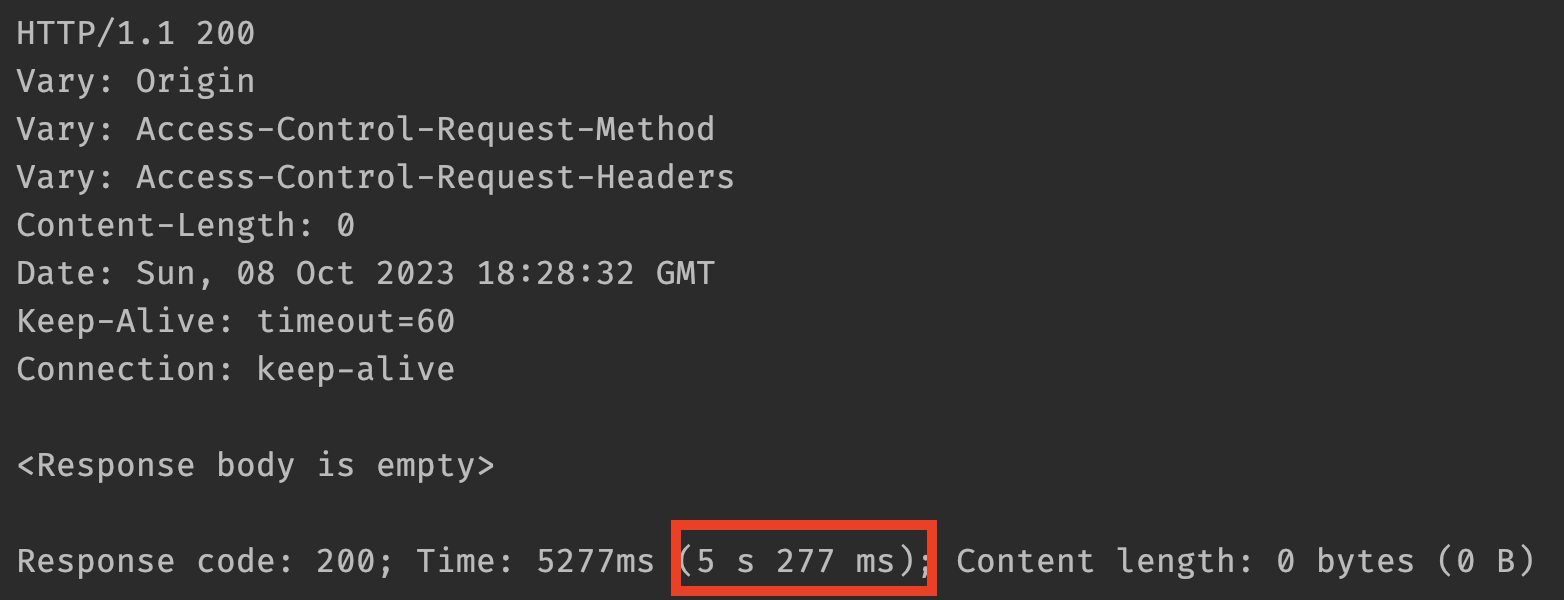
이론상 병렬 처리와 비동기 처리의 차이점은 명백하지만 그리 큰 차이는 안 보이네요. 그래도 병렬 처리보다 리스크가 덜한 방법으로 서드파티 API 호출을 약 500% 개선한 부분은 상당한 이점으로 보입니다.

브라우저에서 요청해도 차이가 별로 안나는 것을 확인할 수 있습니다. 이로써 "내가 할 수 있는 건 다 했다"라고 생각할 뻔했지만 5초라는 시간도 사용자 입장에서는 편하게 기다려줄 수만은 없을 것 같아서 실험을 더 해봤습니다.
페이징과 한계 돌파
영한님 JPA 강의 중에서 페이징과 한계 돌파라는 제목의 강의가 있었던 것으로 기억합니다. 저도 이번에 페이징을 통해서 현재 API 조회시간 5초라는 한계를 돌파해보려고 합니다. 물론 다른 의미지만요.
현재 API 요청 엔드포인트를 보면 per_page 쿼리 스트링이 100으로 지정되어 있습니다. 한 번에 100개의 PR 정보들을 조회한다는 뜻이죠. 해당 엔드 포인트로 요청했을 때 응답시간을 다시 살펴보겠습니다.

한 페이지를 불러오는데 깃허브 서버의 응답만 3.5초를, 데이터를 다운로드하는데 1.2초가 걸립니다. 필자는 아래와 같은 요인들로 인해 응답시간이 더 느린 것이라고 판단했습니다.
- 요청하는 데이터가 많을수록 깃허브 서버의 작업량이 늘어난다.
- PR을 하나만 조회해도 같이 조회되는 정보의 양이 많다.
조회하는 데이터의 수는 같은데 응답시간이 왜 더 빨라지는가?
조회하는 데이터의 수가 같다고 해서 응답시간이 정비례하게 늘었다 줄었다 하는 것은 일반적인 동기 프로그래밍 사고법입니다. 만약 이해가 안 된다면 비동기/non-blocking 또는 병렬 프로그래밍에서의 요청 방식을 다시 고민해 볼 필요가 있습니다.
그럼 기존에 한 번에 불러오던 데이터를 1/10으로 분할하여 한 페이지에 데이터를 10개씩만 조회해 보겠습니다. 아래는 한 페이지에 데이터를 10개씩만 가져올 때의 레이턴시입니다.

약 7배가 빨라진 모습입니다. 그러면 실제 코드 레벨에서도 적용하여 실제 API 응답 시간을 측정해 보겠습니다.
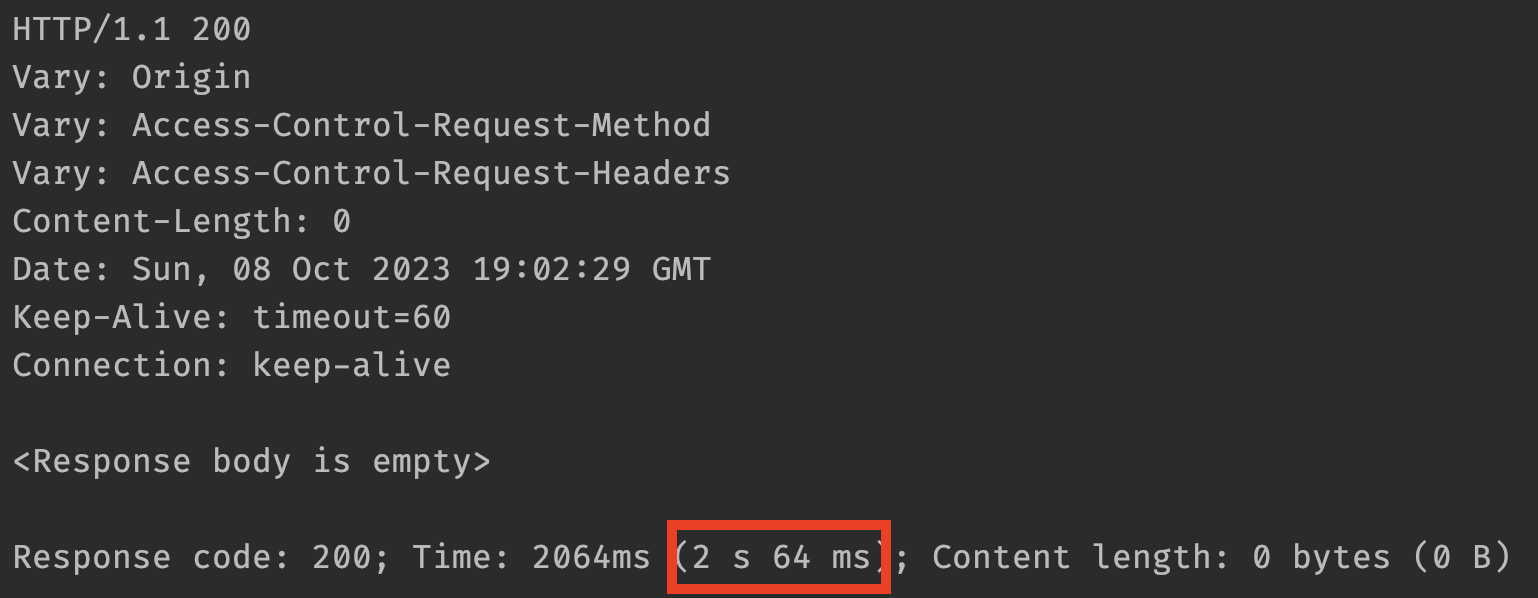
기존에는 24초, non-blocking 처리로 개선 후에는 5초, 페이징까지 고려했을 때는 2초까지 개선된 모습입니다. 단 한 가지 고려해야 할 점은 서드파티에는 API 호출 횟수가 지정되어 있습니다. 페이징을 작게 여러 번 보내면 당연히 시간당 API 호출 가능 횟수가 고갈되는 속도가 빨라지기 때문에 잘 계산해서 요청해야 합니다.
'성능 개선' 카테고리의 다른 글
| [DB] 실전! 집고의 쿼리 성능 개선기 (2) | 2023.10.02 |
|---|---|
| [DB] 이론! 집고의 쿼리 성능 개선기 (2) | 2023.09.26 |
| [Performance] nGrinder를 이용한 서비스 성능 측정 (3) | 2023.09.09 |
