지난 글에 집고팀에서 사용하는 쿼리를 살펴보고 개선 방안들을 도출해봤습니다. 이번 글에서는 실제로 코드와 쿼리를 고쳐보고 클라이언트에서 받는 데이터까지 가공하면 어디까지 개선이 가능한지 더 자세히 살펴보겠습니다.
Entity보다 DTO를
서비스 코드와 Response 프로퍼티들을 분석해본 결과, 아래와 같은 총 4개의 프로퍼티만 필요로 했습니다.
- pet_food_id
- pet_food_name
- brand_name
- pet_food_image_url
public List<GetPetFoodQueryResponse> findPagingPetFoods(
List<String> brandsName,
List<String> standards,
List<String> primaryIngredientList,
List<String> functionalityList,
Long lastPetFoodId,
int size
) {
return queryFactory
.selectDistinct(petFood)
.from(petFood)
.join(petFood.brand, brand)
.join(petFood.petFoodPrimaryIngredients, petFoodPrimaryIngredient)
.fetchJoin()
.join(petFood.petFoodFunctionalities, petFoodFunctionality)
.where(
isLessThan(lastPetFoodId),
isContainBrand(brandsName),
isMeetStandardCondition(standards),
isContainPrimaryIngredients(primaryIngredientList),
isContainFunctionalities(functionalityList)
)
.orderBy(petFood.id.desc())
.limit(size)
.fetch();
}
기존 쿼리가 pet_food 엔티티를 모두 반환하고 있었는데, QueryProjection을 사용하여 DTO만 반환하도록 쿼리를 개선했습니다. 참고로 DTO를 사용하기 때문에 기존에 fetch join이 필요해서 join을 한 부분은 모두 제거했습니다.
public List<GetPetFoodQueryResponse> findPagingPetFoods(
List<String> brandsName,
List<String> standards,
List<String> primaryIngredientList,
List<String> functionalityList,
Long lastPetFoodId,
int size
) {
return queryFactory
.selectDistinct(new QGetPetFoodQueryResponse(
petFood.id,
petFood.name,
brand.name,
petFood.imageUrl
))
.from(petFood)
... 생략
}
이렇게 개선했을 때 기존 48초 걸리던 쿼리가 어느정도 개선되었을까요?

필요하지 않은 컬럼만 제거했을 뿐인데, 약 34초 넘게 빨라졌습니다. 백분율로 계산 시 약 75%의 레이턴시가 줄어든 모습입니다. DTO를 반환하는 것은 단순 컬럼 제거로 인한 성능 개선 뿐만 아니라 N+1 문제와 같은 부수적인 문제들까지 제거해줍니다. 참고로 네이티브 쿼리의 개선 사항은 12s -> 10s의 개선으로 이어졌습니다. 제가 API를 기준으로 설명한 이유는 DTO 반환이 다른 개선 사항들 보다 애플리케이션에 주는 영향이 크기 때문에 언급했습니다.
애플리케이션에서 큰 차이가 나는 이유
약간 웃기지 않나요? 애플리케이션에서는 약 75%의 큰 성능 개선이 이루어진 반면, 쿼리 자체의 개선은 18%입니다. 75%에 비하면 너무 적어보이는 수치라는 생각이 듭니다.
페치 조인의 동작 방식
하지만 실제 사용자가 받을 레이턴세이 대해 개선된 부분은 절대 무시할 수 없는데, 특히 애플리케이션에서 크게 개선된 이유는 지연로딩을 해결하기 위한 페치 조인의 동작 방식에 있습니다.

평소 지연 로딩을 사용할 때 페치 조인과 함께 사용하는 경우가 많았을텐데, 지연 로딩 전략은 해당 객체의 프록시 객체를 만들어 해당 객체를 진짜 사용할 때 실제 객체를 만들고 연관관계를 맺어줍니다.
예를 들어 PetFood와 Brand, PetFoodPrimaryIngredient, PetFoodFunctionality가 모두 지연로딩으로 설정되어 있을 때 해당 PetFood 인스턴스의 연관관계를 직접 호출할 때(Ex. getBrand())가 돼서야 진짜 객체를 만든다는 뜻이죠.
다 알고 있는 내용이겠지만, 위 내용을 설명한 이유는 페치조인 사용 시 지연 로딩 전략이 달라지기 때문입니다.

페치 조인을 사용하게 되면 프록시 객체들이 모두 진짜 객체로 미리 만들어지고 연관관계까지 맺어줍니다. 모든 연관 객체에 대한 프록시 초기화가 미리 이루어진다는 뜻입니다. 하지만 실제로 필요한 데이터가 아닌 경우, 이에 대한 성능 문제가 생길 수 있습니다.
특히 연관관계에 대한 프록시 초기화는 데이터베이스가 아닌 애플리케이션에서 이루어지기 때문에 애플리케이션의 성능이 데이터베이스에 비해 크게 증가한 것이라는 결론을 낼 수 있습니다. 페치 조인은 연관 객체를 조회하는데 완전한 해결책은 아닙니다. 애초에 지연로딩을 피할 수 있다면 피하는게 가장 좋아 보입니다.
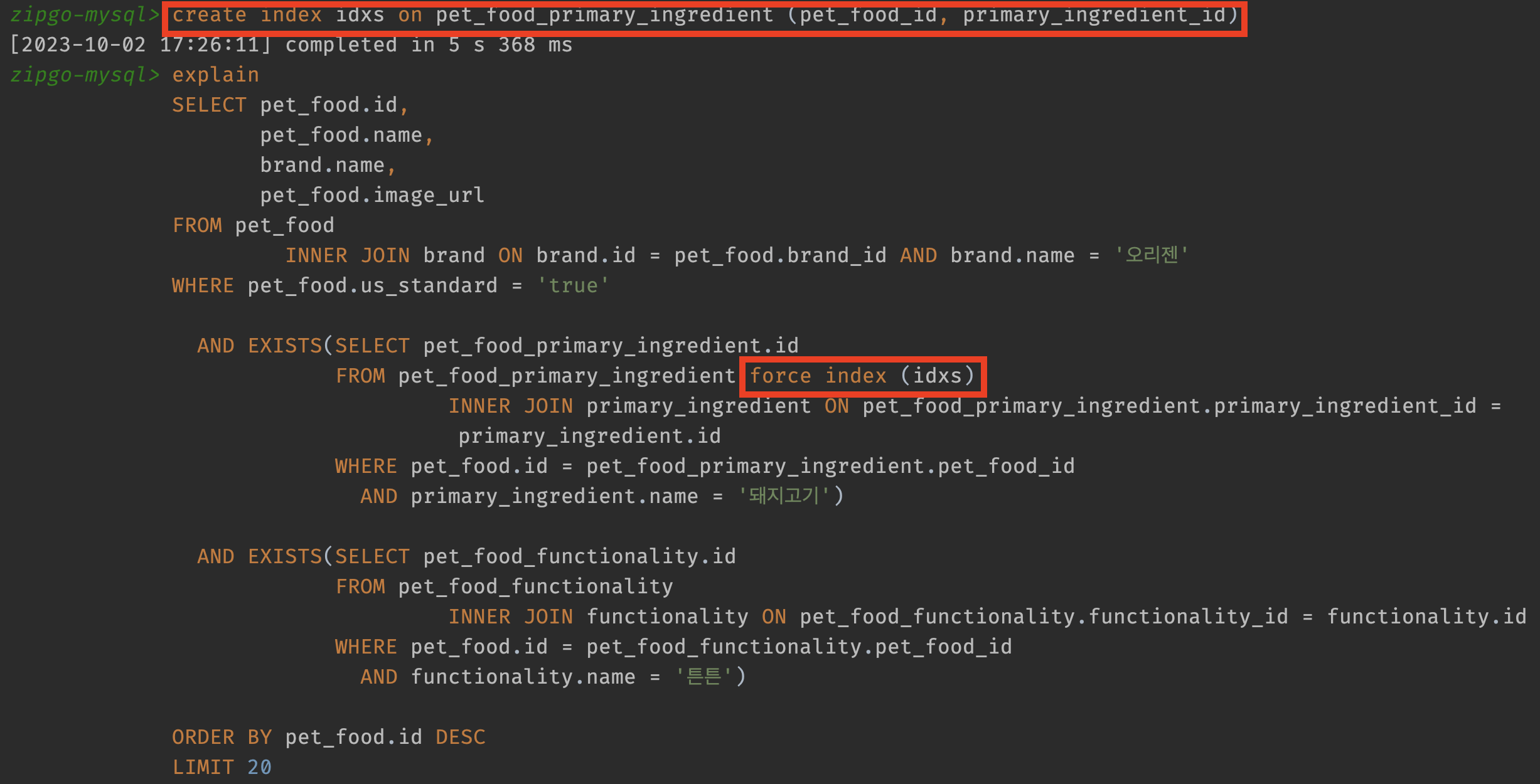
복합 인덱스 설정
복합 인덱스를 설정하기 위한 분석도 진행했었는데, 결론적으로 카디널리티에 관계 없이 조건절의 순서대로 복합 인덱스를 만들기로 했었습니다. (기억이 나지 않거나 잘 모르겠다면 지난 글을 참고해주세요.)

그래서 복합 인덱스를 걸 때 항상 카디널리티가 높은 것을 먼저 선언해야 한다는 것은 아닙니다. 항상 뭐든지 자신의 상황에 맞는 걸 채택하는게 중요한 것 같습니다.
그럼 조건절의 순서에 맞춰서 인덱스를 다시 만들고 실행해보겠습니다.


그럼 원래 10초 걸리던 쿼리가 얼마나 개선되었는지 확인해보겠습니다.

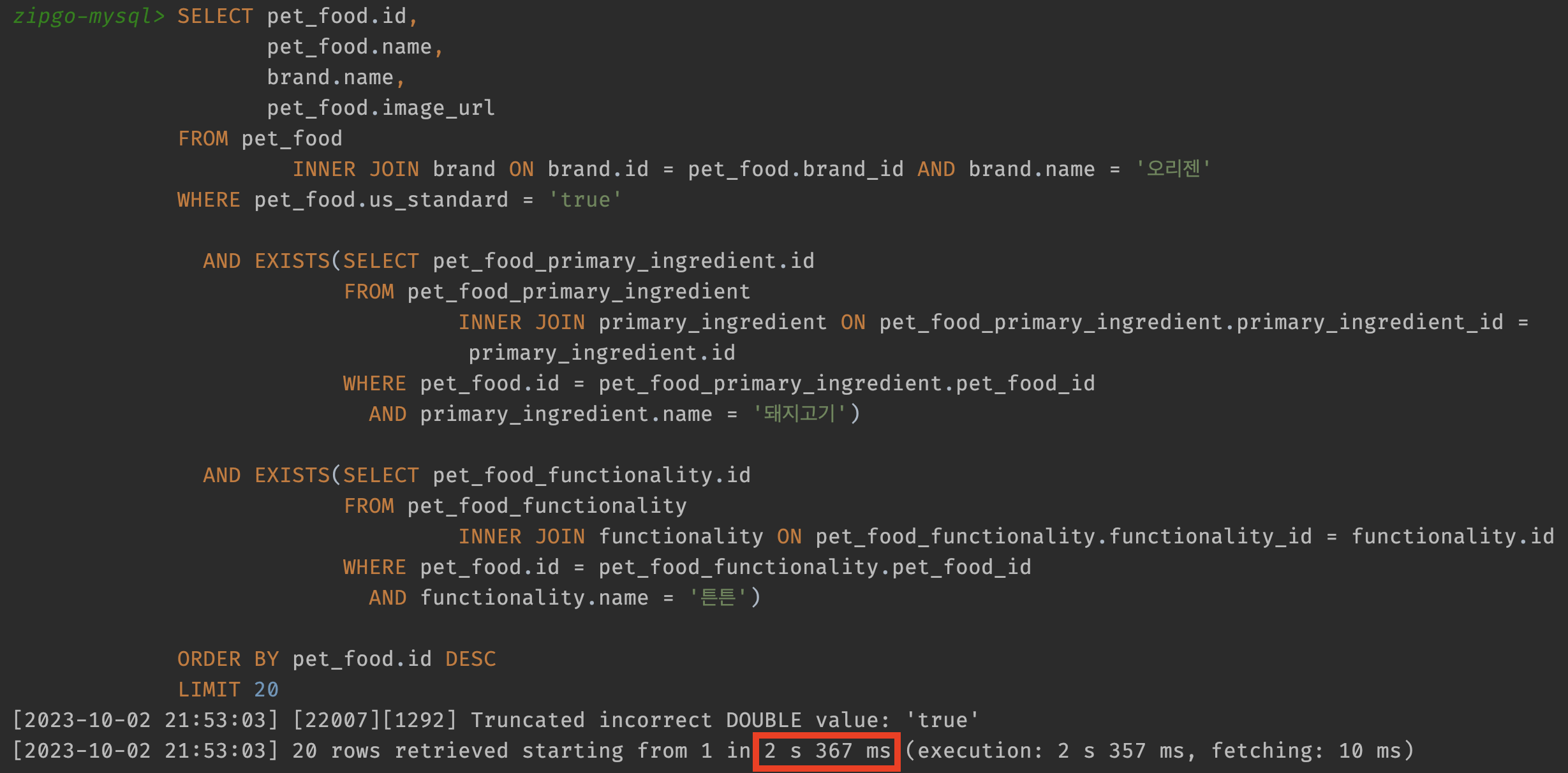
인덱스만으로 해당 쿼리 자체는 10s -> 2s로 약 5배가 빨라졌고, 최종적으로 네이티브 쿼리 기준 12s -> 2s까지 개선된 모습입니다.
id로 조회하기
쿼리 처리 속도가 2초까지 빨라졌지만, 응답을 기다리는 유저 입장에서는 절대 짧은 시간이 아닙니다. 하지만 쿼리를 분리하거나 클라이언트에서 문자열 대신 id를 받는 방법 등 근본적으로 쿼리를 빨라지게 할 수 있는 요인들은 남아있습니다.

이번에는 id로 조회하는 방법을 살펴보려고 합니다. 현재 서브쿼리를 보시면 주원료와 기능성의 이름을 비교하고 있습니다. 즉 문자열을 비교하는 것이죠. 하지만 문자열이 아닌 id로 비교한다면 불필요한 조인을 할 필요도, 개선해야할 테이블도 없어집니다. 이제 id로 비교하면 어떤 결과가 나오는지 확인해보겠습니다.

가장 큰 차이점은 기존 조인을 위해 사용했던 테이블 2개가 사라졌습니다. 또한 더 이상 주원료, 기능성 테이블을 사용하지 않기 때문에 복합 인덱스를 pet_food와 매핑 테이블의 pet_food_id로 설정했습니다. id를 비교하니 매핑 테이블에서 모든게 해결가능해지기 때문이죠. 그럼 쿼리는 몇 초만에 실행될까요?

pet_food 100만건, 매핑 테이블 각각 200만건씩 존재하는 상황에서 복잡한 필터링 쿼리가 단 0.06초만에 조회가 완료되었습니다. 12초에서 0.06초면 정확히 200배 빨라졌습니다.
사실 이 글이 나오기까지 시간이 생각보다 오래걸렸습니다. 데이터베이스고 인덱스고 잘 몰랐던 부분을 삽질하는 시간이 많았기 때문이죠. 무엇보다 이론적인 지식과 실제 쿼리 실행 계획이 안맞았던 부분들이 너무 힘들었습니다.
그래도 항상 새로운 지식을 학습하는 과정이 즐겁습니다. 시간을 투자하는 만큼의 성취감이 따라오니까요. 동시에 느끼는건 공부할 수록 공부할게 더 생긴다는 것입니다. 그런 의미로 다음 글은 애플리케이션 단의 코드를 만져서 더 고도화를 해보겠습니다. 읽어주셔서 감사합니다.
'성능 개선' 카테고리의 다른 글
| [Performance] 서드파티 API를 사용할 때 고려할 수 있는 최선의 방법들 (2) | 2023.10.08 |
|---|---|
| [DB] 이론! 집고의 쿼리 성능 개선기 (2) | 2023.09.26 |
| [Performance] nGrinder를 이용한 서비스 성능 측정 (3) | 2023.09.09 |
